
Video Highlights
Solving complex robot manipulation tasks requires a Task and Motion Planner (TAMP) that searches for a sequence of symbolic actions, i.e. a task plan, and also computes collision-free motion paths. As the task planner and the motion planner are closely interconnected TAMP is considered a challenging problem. In this work, a Probabilistic Integrated Task and Motion Planner (PROTAMP-RRT) is presented. The proposed method is based on a unified Rapidly-exploring Random Tree (RRT) that operates on both the geometric space and the symbolic space. The RRT is guided by the task plan and it is enhanced with a probabilistic model that estimates the probability of sampling a new robot configuration towards the next sub-goal of the task plan.

Depth images usually contain pixels with invalid measurements. This work presents a deep learning approach that receives as input a partially-known volumetric model of the environment and a camera pose, and it predicts the probability that a pixel would contain a valid depth measurement if a camera was placed at the given pose. The method was integrated into a CNN-based probabilistic Next Best View planner, resulting in a more realistic prediction of the information gain for each possible viewpoint with respect to state of the art approaches.
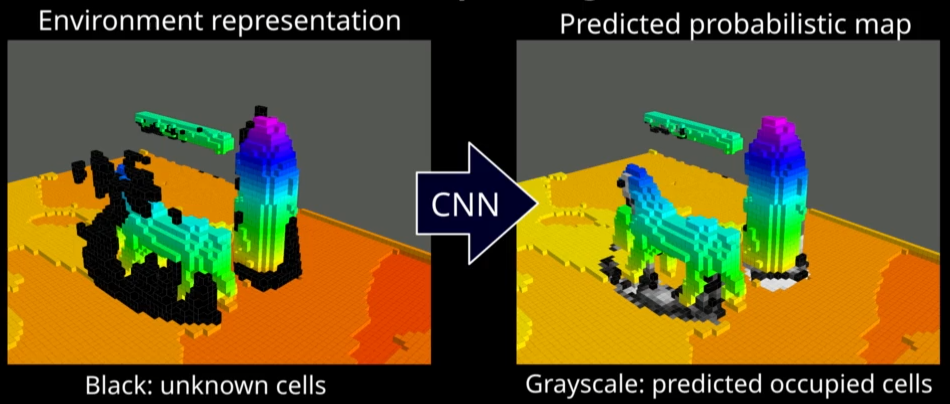
A method to plan the next best view of a depth camera by leveraging on a Convolutional Neural Network (CNN), and on a probabilistic occupancy map of the environment for ray casting operations. In particular, a hybrid approach is introduced that exploits the convolutional encoder-decoder to perform object completion, and an algorithm based on ray casting to evaluate the information gain of possible sensor view poses. Automatic object completion consists of inferring the occupancy probability of the regions of space that have not been observed. A comparison against several methods, including City-CNN, was carried out in 2D and 3D environments on publicly available datasets. Experiments indicate that the proposed method achieves the best results in terms of exploration accuracy.

This work presents a surfel-based method for multi-view 3D reconstruction of the boundary between known and unknown space. The approach integrates multiple views from a moving depth camera and it generates a set of surfels that encloses observed empty space, i.e., it models both the boundary between empty and occupied space, and the boundary between empty and unknown space. The method does not require a persistent voxel map of the environment to distinguish between unknown and empty space. The problem is solved thanks to an incremental algorithm that computes the Boolean union of two surfel bounded volumes: the known volume from previous frames and the space observed from the current depth image.

This work presents an approach for part-based grasp planning in point clouds. A complete pipeline is proposed that allows a robot manipulator equipped with a range camera to perform object detection, categorization, segmentation into meaningful parts, and part-based semantic grasping. A supervised image-space technique is adopted for point cloud segmentation based on projective analysis. Projective analysis generates a set of 2D projections from the input object point cloud, labels each object projection by transferring knowledge from existing labeled images, and then fuses the labels by back-projection on the object point cloud.

This work presents an approach for humanoid Next Best View (NBV) planning that exploits full body motions to observe objects occluded by obstacles. The task is to explore a given region of interest in an initially unknown environment. The robot is equipped with a depth sensor, and it can perform both 2D and 3D mapping. The robot is guided by two behaviors: a target behavior that aims at observing the region of interest by exploiting body movements primitives, and an exploration behavior that aims at observing other unknown areas. Experiments show that the humanoid is able to peer around obstacles to reach a favourable point of view.

This work presents a novel approach for automatic floorplan generation of indoor environments. The floorplan is computed from a large-scale point cloud obtained from registered terrestrial laser scans. In contrast to previous work, the proposed method does not assume either a flat ground, or flat ceiling, or planar walls. Moreover, the method exploits the detection of structural elements, i.e., parts having a constant section over the entire height of the building (such as walls and columns), which is beneficial in cluttered regions to compensate for the lack of information due to occlusions. The evaluation was performed in complex buildings, like industrial warehouses, that include machines and pallet racks, whose layout is included in the generated floorplan. The algorithm achieves a floorplan reconstruction with accuracy comparable to the resolution of the adopted sensor. Results are also compared to a ground truth acquired using a total station.
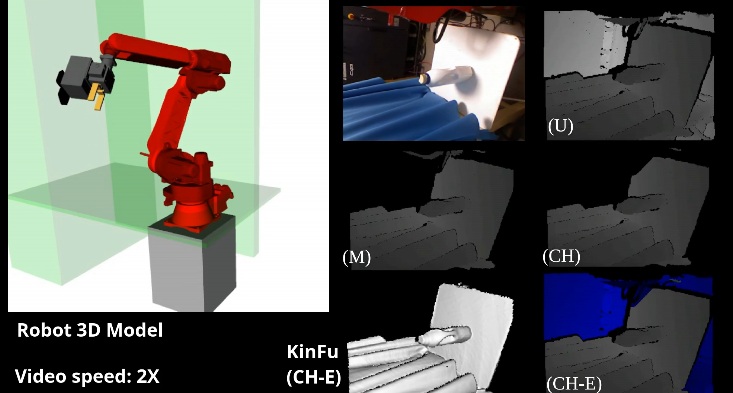
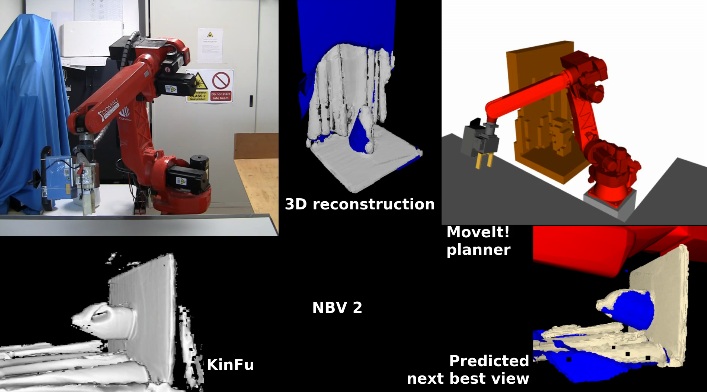
This work investigates the use of a real-time self filter for a robot manipulator in next best view planning tasks. The robot is equipped with a depth sensor in eye-in-hand configuration. The goal of the next best view algorithm is to select at each iteration an optimal view pose for the sensor in order to optimize information gain to perform 3D reconstruction of a region of interest. An OpenGL-based filter was adopted, that is able to determine which pixels of the depth image are due to robot self observations. The filter was adapted to work with KinectFusion volumetric based 3D reconstruction. Experiments have been performed in a real scenario. Results indicate that removal of robot self observations prevents artifacts in the final 3D representation of the environment. Moreover, view poses where the robot would occlude the target regions can be successfully avoided.
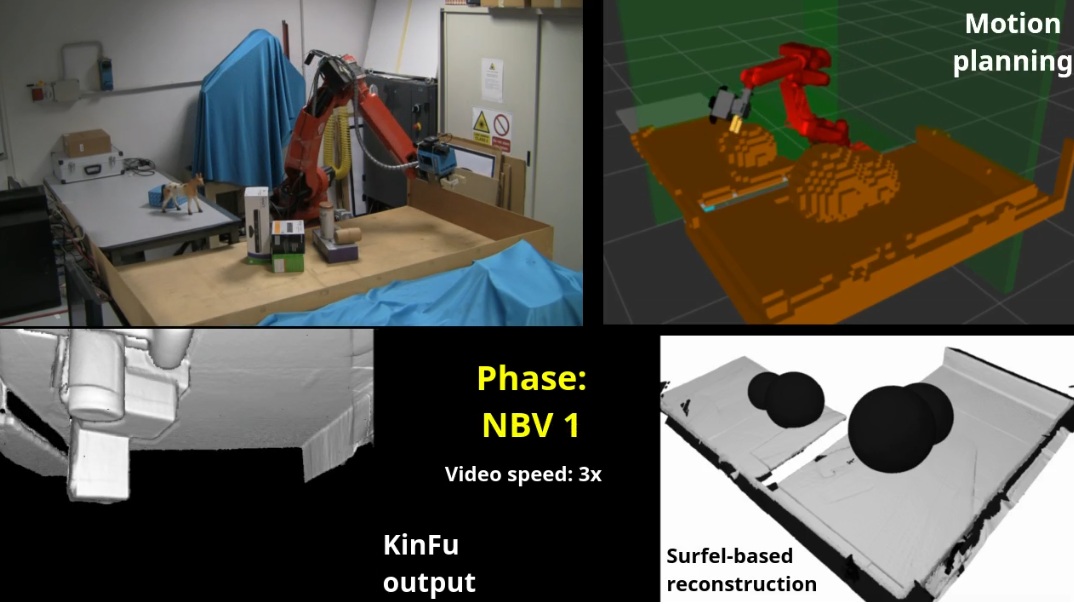
The most expensive phase of Next best view (NBV) computation is the view simulation step, where the information gain of a large number of candidate sensor poses are estimated. Usually, information gain is related to the visibility of unknown space from the simulated viewpoint. A well-established technique is to adopt a volumetric representation of the environment and to compute the NBV from ray casting by maximizing the number of unknown visible voxels. This work explores a novel approach for NBV planning based on surfel representation of the environment. Surfels are oriented surface elements, such as circular disks, without explicit connectivity. A new kind of surfel is introduced to represent the frontier between empty and unknown space. Surfels are extracted during 3-D reconstruction, with minimal overhead, from a KinectFusion volumetric representation. Surfel rendering is used to generate images from each simulated sensor pose. The proposed approach achieves better performance than volumetric algorithms based on ray casting implemented on graphics processing unit (GPU), with comparable results in terms of reconstruction quality.
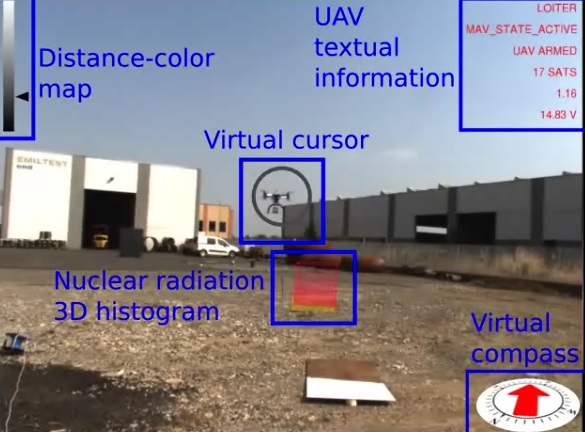
A visuo-haptic augmented reality (VHAR) interface is presented that enables teleoperation of an unmanned aerial vehicle (UAV) equipped with a custom CdZnTe-based gamma-ray detector. The task is to localize nuclear radiation sources without the close exposure of the operator. The aim of the VHAR interface is to increase the situation awareness of the operator. The user teleoperates the UAV using a 3DOF haptic device that provides an attractive force feedback around the location of the most intense detected radiation source. A fixed camera on the ground observes the environment where the UAV is flying. A 3D augmented reality scene is displayed on a computer screen accessible to the operator. Multiple types of graphical overlays are shown, including sensor data acquired by the nuclear radiation detector.
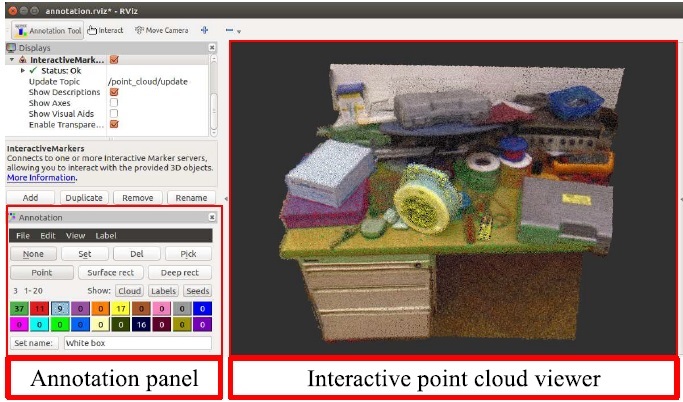
A user-friendly approach for multilabel point cloud annotation. The method requires the user to select sparse control points belonging to the objects through a mouse-based interface. The software utilizes the selected control points to perform a segmentation algorithm on the neighborhood graph, based on shortest path tree. The method has been evaluated by multiple users and compared with a standard rectangle-based selection technique. Results indicate that the proposed method is perceived as easier to use, and that it allows a faster segmentation even in complex scenarios with occlusions.

A method is proposed for ground segmentation in large-scale point clouds of industrial environments acquired using a terrestrial laser scanner (TLS). In contrast to many previous works experiments have been performed in large-scale point clouds that contain over 10^10 points measured from multiple scan stations. The proposed solution is based on a robust estimation of points belonging to the ground below each scan station and it can be applied even in challenging scenarios with nonplanar regions.
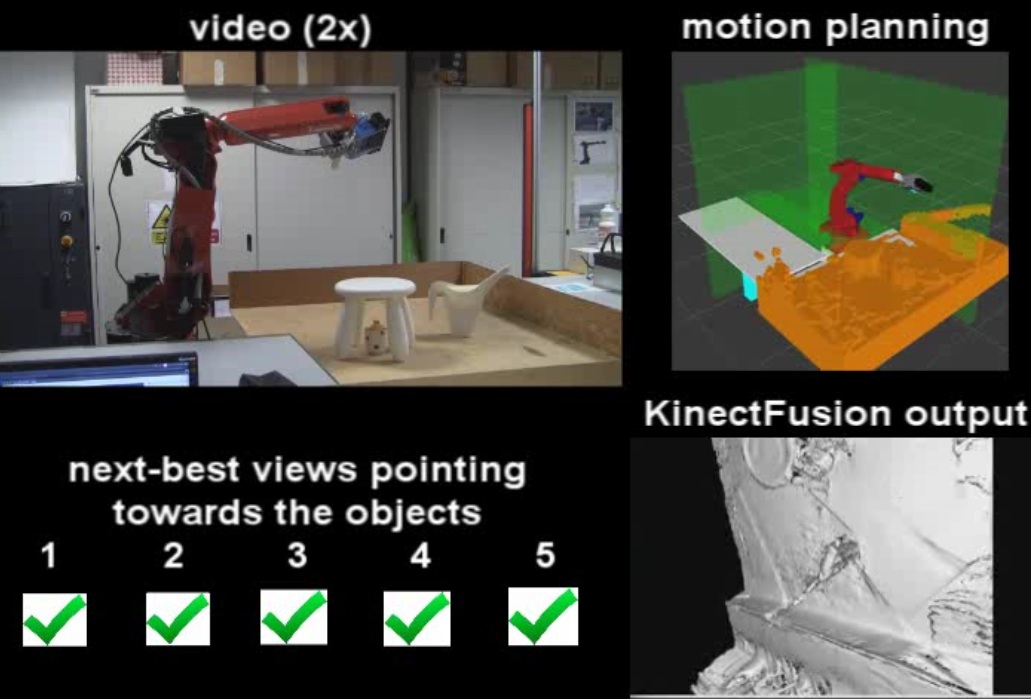
A novel strategy to determine the next-best view for a robot arm, equipped with a depth camera, which is oriented to autonomous exploration of unknown objects. The next-best view is chosen to observe the border of incomplete objects. Salient regions of space that belong to the objects are detected, without any prior knowledge, by applying a point cloud segmentation algorithm. The system uses a Kinect V2 sensor and it exploits KinectFusion to maintain a volumetric representation of the environment. Experiments indicate that the proposed method enables the robot to actively explore the objects faster than a standard next-best view algorithm.

A haptic teleoperation system of an unmanned aerial vehicle (UAV) aimed at localizing radiation sources in outdoor environments. Radiation sources are localized and identified by equipping the UAV with a CdZnTe-based custom X-ray detector. The system allows exploration of potentially dangerous areas without a close exposure of the human operator. The operator is able to provide motion commands to the UAV while receiving force feedback from a 3DOF haptic interface. Force feedback provides an attractive basin around the location of the most intense detected radiation.
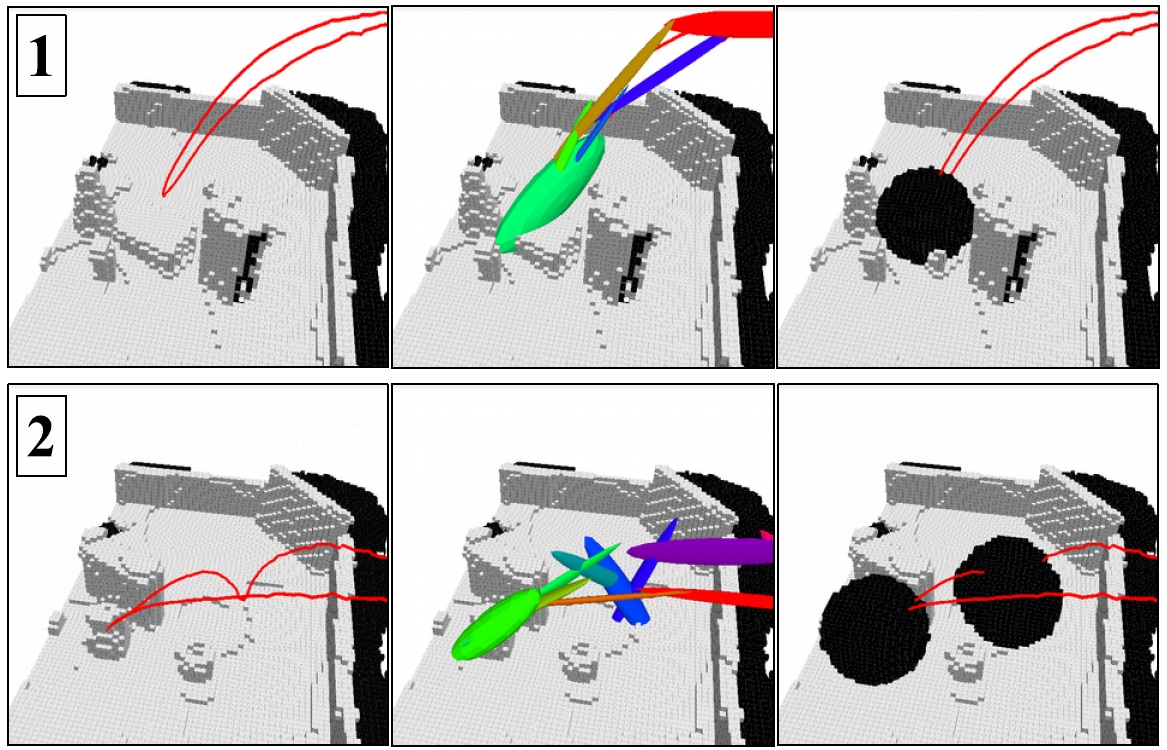
A spatial attention approach for a robot manipulator equipped with a Kinect range sensor in eye-in-hand configuration. The location of salient object manipulation actions performed by the user is detected by analyzing the motion of the user hand. Relevance of user activities is determined by an attentional approach based on Gaussian mixture models. A next best view planner focuses the viewpoint of the eye-in-hand sensor towards the regions of the workspace that are most salient. 3D scene representation is updated by using a modified version of the KinectFusion algorithm that exploits the robot kinematics.
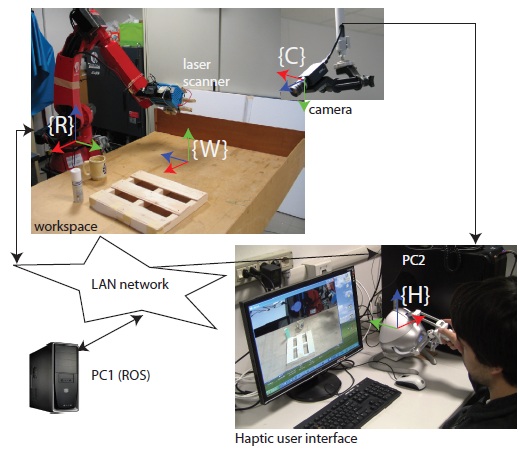
Visuo-haptic augmented reality system for programming object manipulation tasks by demonstration. A desktop augmented reality system in which the user is not co-located with the environment and a 3DOF haptic device, providing force feedback, is adopted for user interaction. The interaction paradigm allows the user to select and manipulate virtual objects superimposed upon a visual representation of the real workspace. The approach also supports physics-based animation of rigid bodies. In the proposed method automatic object recognition and registration are performed from 3D range data acquired by a laser scanner mounted on a robot arm. The experiment shows an application of the augmented reality system for programming manipulation tasks by demonstration.
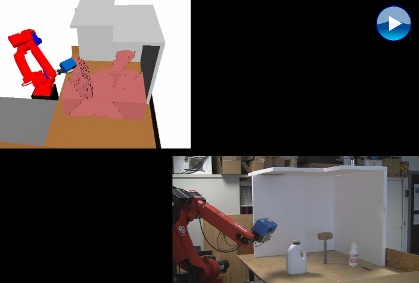
Autonomous robot exploration of unknown objects by sensor fusion of 3D range data. The approach aims at overcoming the physical limitation of the minimum sensing distance of range sensors. Two range sensors are used with complementary characteristics mounted in eye-in-hand configuration on a robot arm. The first sensor operates at mid-range and is used in the initial phase of exploration when the environment is unknown. The second sensor, providing short-range data, is used in the following phase where the objects are explored at close distance through next best view planning.
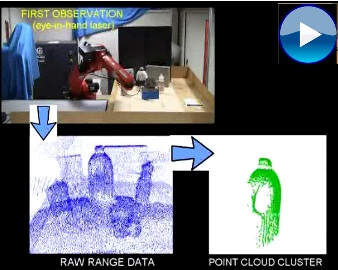
Like humans, robots that need semantic perception and accurate estimation of the environment can increase their knowledge through active interaction with objects. A method for 3D object modeling is proposed for a robot manipulator with an eye-in-hand laser range sensor. Since the robot can only perceive the environment from a limited viewpoint, it actively manipulates a target object and generates a complete model by accumulation and registration of partial views.
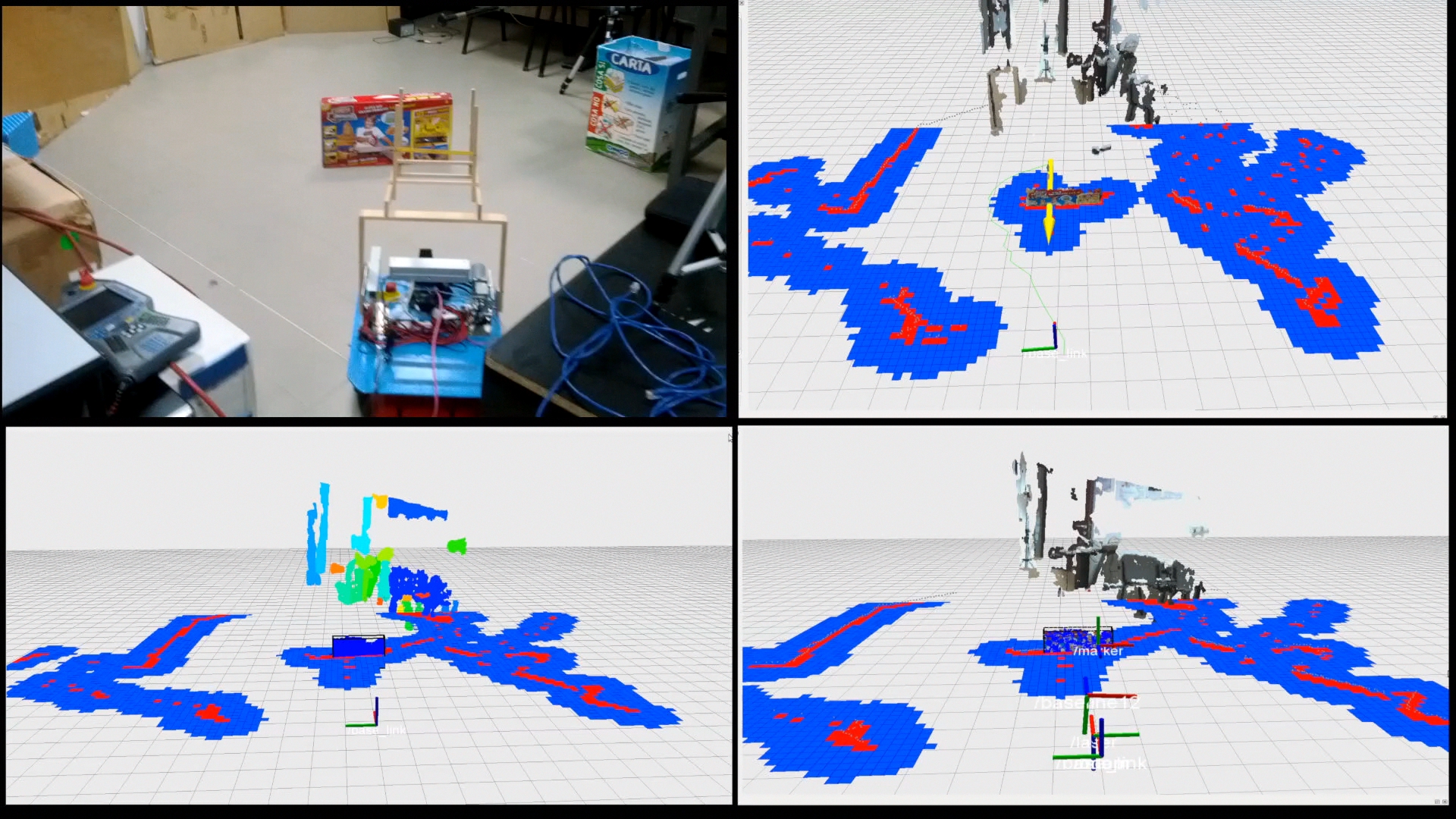
A viewpoint planning and local navigation algorithm for mobile robot exploration using stereo vision and laser scans. First, the algorithm acquires an merges into a single point cloud the sensor measurements and updates a 2D occupancy grid map. Next, the point cloud is segmented into clusters (candidate objects) and a target robot viewpoint is selected in order to observe one of the clusters. Finally, the robot follows the path computed by the navigation algorithm using the occupancy grid map.


A method for gesture recognition and humanoid imitation based on Functional Principal Component Analysis (FPCA). FPCA is an extension of multivariate PCA that provides functional principal components which describe the modes of variation in the data. In the proposed approach FPCA is used for both unsupervised clustering of training data and gesture recognition. Human hand paths in Cartesian space are reconstructed from inertial sensors or range data (using Kinect). Recognized gestures are reproduced by a small humanoid robot.
Info
First place for team "Redbeard Button" from the University of Parma at Sick Robot Day 2012. The robotic competition took place on October 6th and the robot has to detect, pick and bring the green balls to the pen. The mobile robot has been able to pick 7 balls in 10 minutes. The competition allowed Rimlab to test multi-sensor based perception, localization and mapping algorithms in a changing environments and mobile robot navigation.


A method for robot to human object hand-over is presented that takes into account user comfort. Comfort is addressed by serving the object to facilitate user's convenience. The object is delivered so that the most appropriate part is oriented towards the person interacting with the robot. The robot system also supports sensory-motor skills like object and people detection, robot grasping and motion planning. The experimental setup consists of a six degrees of freedom robot arm with both an eye-in-hand laser scanner and a fixed range sensor.

A method for robot manipulation from range scan data. The approach is focused on part-based object categorization and grasping. Topological shape segmentation is used for the identification of grasp affordances with an efficient data structure for encoding proximity data.
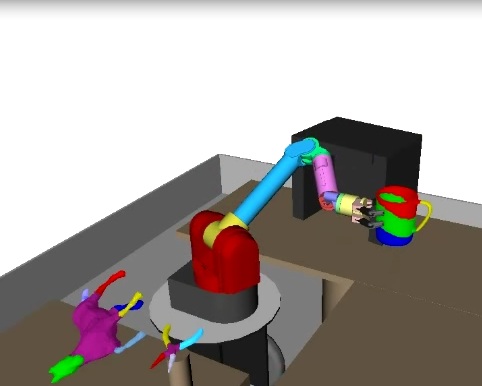
A method for robot manipulation planning is presented that enables semantic grasping of previously unseen objects. The approach is based on programming by demonstration in virtual reality and 3D shape segmentation. Topological shape segmentation enables both object retrieval and part-based grasp planning according to the affordances of an object.
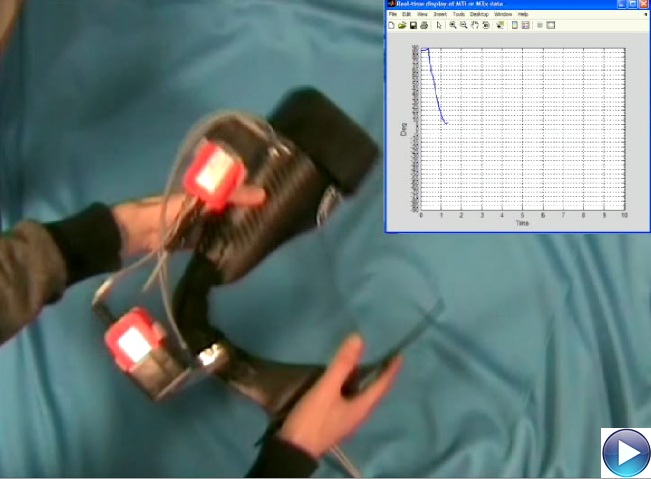
Ankle-foot orthoses (AFOs) are prescribed to individuals with walking disabilities. This project seeks a solution for assessing the efficacy of AFOs in a continuous and non-invasive manner. Ankle joint angle is identified as an important metric for this assessment since it allows to detect typical behaviours of the beneficiary that uses the AFO. The first part of this research aims to develop a system that is able to compute the ankle angle.

Augmented Reality (AR) technologies allow the user to see the real world, with computer generated data superimposed upon the real workspace. A visuo-haptic AR environment is proposed that includes a three dof haptic device for user interaction and supports realistic physics-based animation of virtual objects.
We have developed a visual hand tracking and gesture recognition system based on a monocular camera system for interactive VR tasks.

We have developed a low-cost bimanual glove interface for interactive VR tasks. The interface is based on LEDs and the Nintendo WiiMote.
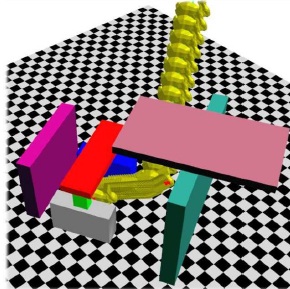
A novel approach for efficient disassembly planning of rigid bodies has been introduced. The method allows computation of all the physically stable subassembly configurations and all the possible destructive disassembly sequences of a set of objects. Optimizations based on precedence relations and geometrical clustering have been proposed. A nondestructive algorithm for computing feasible disassembly paths has also been integrated.


A desktop virtual reality system which offers real-time user interaction and realistic physics-based animation of rigid objects. The system is built upon a graphical engine which supports scene graphs, and a physics-based engine which enables collision detection. Full hand pose estimation is achieved through a dataglove and motion tracker..

Physics-based animation is becoming an essential feature for any advanced simulation software. We explore potential benefits of physics-based modeling for task programming in virtual reality. We show how realistic animation of manipulation tasks can be exploited for learning sequential constraints from user demonstrations.

Mobile manipulation experiments with marked-based visual servoing.
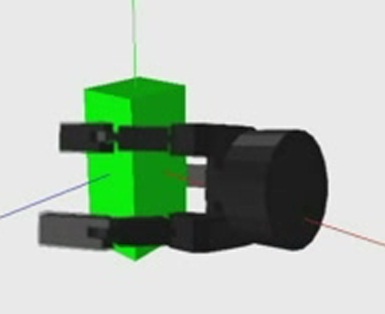
Automatic environment modeling is an essential requirement for intelligent robots to execute manipulation tasks. A method for synthesizing robot grasps from demonstration is presented. The system allows learning and classification of human grasps demonstrated in virtual reality as well as teaching of robot grasps and simulation of manipulation tasks. Both virtual grasp demonstration and grasp synthesis take advantage of an approach for automatic workspace modeling with a monocular camera. The method is based on the computation of edge-face graphs.

A path specification system based on imitation of human walking path for a humanoid robot. The experimental system investigated comprises a Robosapien V2 humanoid and includes multiple sensor devices such as an electromagnetic tracker, and a monocular vision system.


Experiments with RobosapienV2 and the Nintendo WiiMote.
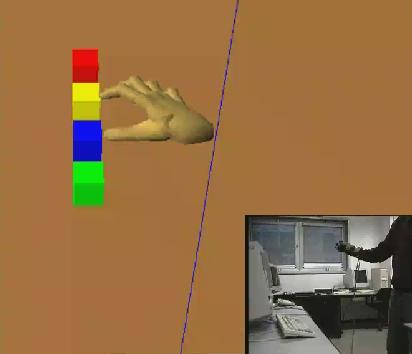
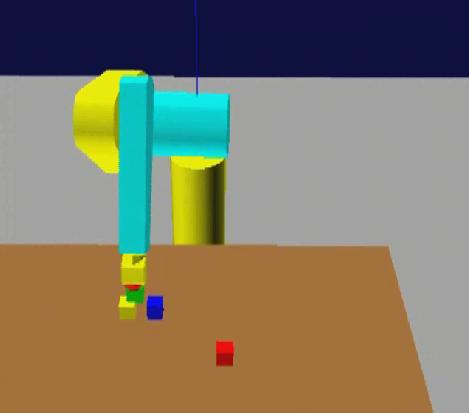

Early work on robot programming by demonstration (PbD) in virtual reality. The user wearing a CyberTouch glove performs a task in a virtual workspace which simulates the real environment. The operator's movements are analysed and interpreted as high level operations, then the system translates the recognized sequence into manipulator-level commands. The manipulation task is finally replicated both in a predictive simulation and in the real workspace. The objects can be picked up and moved in the environment thanks to a collision detection routine and a grasping algorithm. After the demonstration phase the task planner automatically generates an abstract representation of the observed task as a sequence of high level pick & place operations. If the simulation gives an adequate result the user can start the real execution of the task. The effectiveness of the system has been tested in our laboratory with a PUMA 560 arm.